Learning Translations via
Matrix Completion
ABSTRACT
I was part of a large team led by Derry Wijyaya, in collaboration with Brendan Callahan , John Hewitt , Jie Gao, Marianna Apidianaki. Supervised by Chris Callison-Burch. The paper was published in ACL 2017 (25% acceptance rate). Bilingual lexicon induction is the task of learning word translations without bilingual parallel corpora. In this paper published in ACL 2017, we model bilingual lexicon induction as a matrix completion problem leveraging diverse set of data from text to images, each of which is allowed to be incomplete or noisy. Specifically, we construct a matrix with source words in the columns and target words in the rows, and formulate translation as matrix factorization with a Bayesian Personalized Ranking objective (BPR). This objective is appropriate because the absence of values in the matrix does not imply a missing translation, and BPR cast the prediction of missing values as a ranking task. The framework is tested on the VULIC1000 data set comprising of 1000 nouns in Spanish, Italian, and Dutch, and their one-to-one ground-truth translations in English, outperforming the state-of-the art models by significant margin.
INTRODUCTION

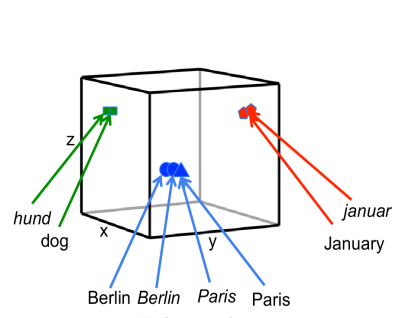
Machine translation between languages is a crucial step in bringing the world together. However machine translation requires large, sentence aligned bilingual texts to learn effective models, and such corpora is rare, especially for resource-constrained languages, and result in inaccurate translations. Due to the low quantity and thus coverage of the texts, there may still be “out-of-vocabulary” words encountered at run-time. The Bilingual Lexicon Induction (BLI) task which learns word translations from monolingual or comparable corpora to increase word coverage. Past attempts have often relied on simple count based methods, however the feature vectors constructed such way typically only support heuristic notion of distance. In recent years, there has been a resurgence of interest in word embeddings learned by recurrent neural networks (RNNs) that supports better notion of word similarities in certain tests. Recent work in machine translation leveraged such advances by constructing a shared bilingual embedding space spanned by the same basis, in this shared space words of the same meaning from different languages are distributed close together, providing an immediate measure to determine translations (see Fig 1). Typically, the transformation between the semantic space between two languages is induced using seed translations from existing dictionaries, or reliably extracted from pseudo-bilingual copra of comparable tasks. Recent work by Vulic et al. (2016) and others showed what naively combining word embeddings with visual similarities from images can improve translation accuracy. We extend prior attempts by constructing a unified framework to integrate signals from monolingual, bilingual, and image data to improve accuracy of machine translation.
PROBLEM FORMULATION
Overview
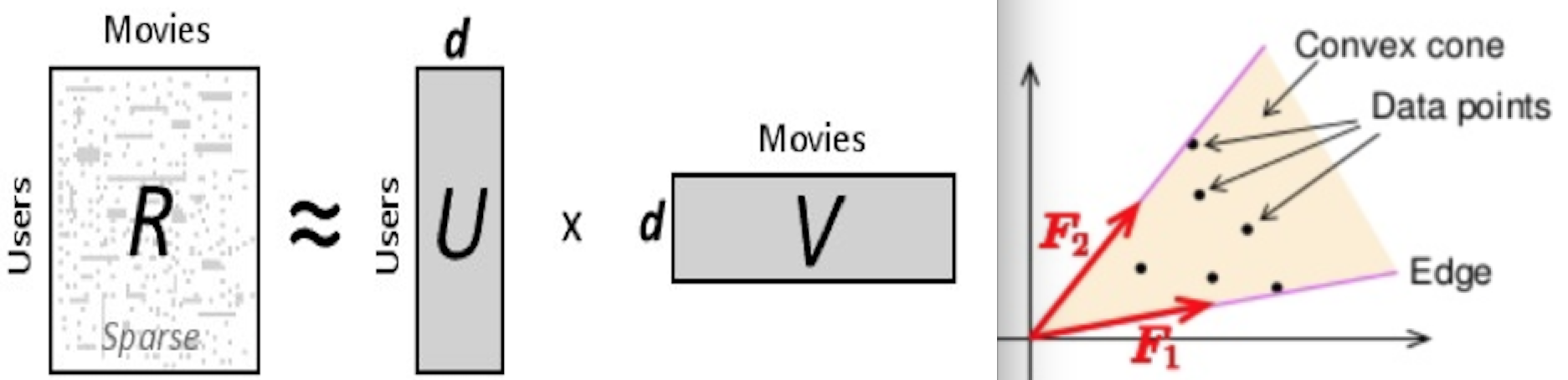
Our approach is based on extensions to the probabilistic model of matrix factorization (MF) in collaborative filtering. We represent our translation task as a matrix with source words in the columns and target words in the rows (Figure 1). Based on observed translations in the matrix found in a seed dictionary, our model learns low-dimensional feature vectors that encode the latent properties of the words in the row and the words in the column. The dot product of these vectors, which indicate how “aligned” the source and the target word properties are, captures how likely they are to be translations. Missing values in the matrix are interpreted as missing translations. Bayesian Personalized Ranking approach to Matrix Factorization (Rendle et al., 2009) formulates the task of predicting missing values as a ranking task. With the assumption that observed true translations should be given higher values than unobserved translations, BPR learns to optimize the difference between values assigned to the observed translations and values assigned to the unobserved translations. However bilingual dictionaries do not exist for some languages, thus existing formulation of MF with BPR suffers from the “cold start” issue. We mitigate the problem by incorporating monolingual signals of translation equivalence, and visual representations of words extracted from images by AlexNet.
Details
Specifically, given a set of source words F and a set of target words E, and the pair of words (e,f) where e ∈ E and f ∈ F, (e,f) is a candidate translation with an associated score xe,fMF ∈ [0, 1], we wish to generate the missing translations. That is given any arbitrary tuple (e,f), we wish wish to assign a value xe,fMF stating how likely f translates to e. Using matrix factorization, we can decompose the matrix XMF of xe,fMF into two low-rank matrices:
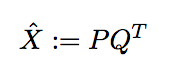
so that each xe,fMF = pe qf. We solve the cold-start problem alluded above by computing an auxiliary value xe,fAUX using other features associated with each word:
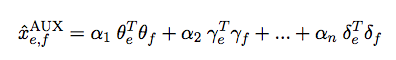
in this case θe is the visual features extracted by AlexNet, and each αi is another auxiliary feature. Note all the parameters in the expression are learned. Note although it is possible to combine xe,fMF and xe,fAUX by addition, we note that xe,fMF has high precision but low recall, and vice versa for xe,fAUX. Thus we only back-off to xe,fAUX for words that have too few associated translations.
Learning for Bayesian Personalized Ranking involves maximizing the difference in values assigned to observed translations compared to those assigned to unobserved translations. That is given a training set of triples: (e, f, g) so that e translates to f, but not to g, we want to maximize the difference:
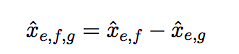
Specifically, for logistic sigmoid function σ, parameter vector Θ with values xe,f,g, and hyperparameter λΘ the objective function of BPR is to maximize the sum of log triplet score differences subject to sparsity penalty:
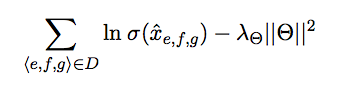
The model is trained using stochastic gradient descent.
DATASET AND EXPERIMENTS
We benchmark our method on two tests sets:
- VULIC1000: 1000 nouns in Spanish, Italian, and Dutch, along with their one-to-one ground-truth word translations in English.
- CROWDTEST: a larger set of 27 languages from crowdsourced dictionaries.
For each language, we randomly pick up to 1000 words that have only one English word translation in the crowdsourced dictionary to be the test set for that language. On average, there are 967 test source words with a variety of POS per language. Furthermore, we construct another bilingual translation dataset WIKI, using interlingual links among Wikipedia pages to identify words in a third language that translates to words in the source and target language. And finally, we construct WIKI + CROWD comprised of a set of translations from the source to non-target languages, pivoted through wikipedia pages. We test the efficacy of our algorithm in these four studies using the datasets we collected:
- xe,fMF-W Monolingual signals for translation: using WIKI.
- xe,fMF-W+C Monolingual signals for translation: using WIKI+CROWD
- xe,fAUX-WEBilingual informed word embeddings: the source and target embeddings are learned using word2vec skiagram model on tokenized Wikipedia pages. And the mapping between two embeddings are learned with crowdsourced translations as seed. The linear mapping minimizes squared error after translation:
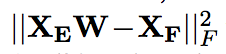
where XE and XF are source and target languages, while W is the transformation between the two sets.
- xe,fAUX-VIS Visual representation of words: We use a large multilingual corpus of labeled images to obtain the visual representation of the words in our source and target languages. The corpus contains 100 images for up to 10k words in each of 100 foreign languages, plus images of each of their translations into English. For each word, we use 10 images from the dataset and extract feature representation using a four layer neural net W = (φ(1), φ(2), φ(3), φ(4)) trained with the objective:
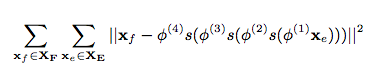
where xe and xf are source and target words.
Finally, during testing we combine two auxiliary signals word embeddings and image embeddings with: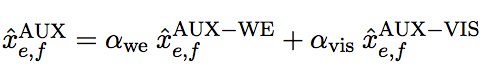
and output the translation probability according to: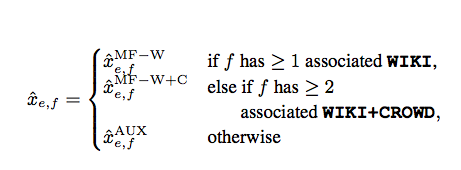
RESULTS AND DISCUSSION
Using the back-off scheme we described before, we run the following six set of experiments:
- BPR_W uses only xe,fMF-W
- BPR_W+C uses xe,fMF-W with back-off to xe,fMF-W+C
- BPR_LN uses only xe,fAUX-WE with linear mapping as described in III
- BPR_NN uses only xe,fAUX-WE with nonlinear mapping as seen in IV
- BPR_WE uses xe,fMF-W, xe,fMF-W+C and xe,fAUX-WE with nonlinear mapping
- BPR_VIS uses xe,fMF-W, xe,fMF-W+C, and combines xe,fAUX-WE with xe,fAUX-VIS as described above.
We benchmark each of the methods against the state of the art baseline model on the VULIC1000 dataset: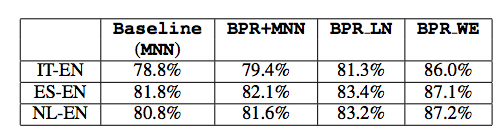
The baseline mutual nearest neighbor method (MNN) uses mutual nearest neighbor pairs (MNN) obtained from pseudo-bilingual corpora constructed from unannotated monolingual data of the source and target languages, and ranks candidate target words based on their cosine similarities to the source word in the shared space. As we can see above, our methods perform better across all translation pairs, in particular when multi-modal information is used for translation. We observe a similar trend in the CROWDTest data. 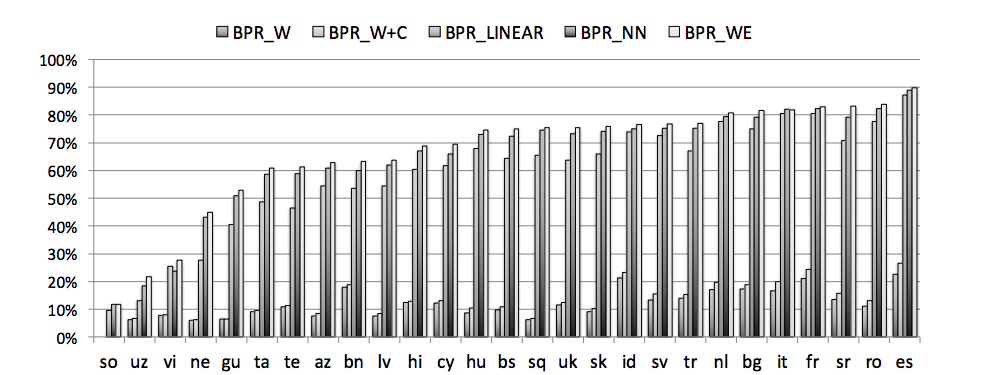
Finally, we noted that a seed lexicon size of 5k is sufficient to achieve optimal performance across languages, although it is unclear why this is. In conclusion, in this project we proposed a novel framework for combining multi-modal data from diverse sources, each of which may be sparse or noisy. The framework is based on matrix completion and use BPR to learn translations. Our method is effective across different languages, and accuracy improves as the volume of data increases. Finally, our framework can trivially incorporate additional signals.