Massive Multilingual Corpus for
Learning Translations From Images
ABSTRACT
I was part of a multi-year project led by Brendan Callahan , in collaboration with John Hewitt and Derry Wijyaya, supervised by Chris Callison-Burch. In this project, we introduce a new large scale multilingual corpus of labeled images collected to facilitate research in learning translations via visual similarity. We have collected 100 images for up to 10,000 words in each of 100 foreign languages, and images for each of their translations into English. In addition, we collected the text from the web pages where each of the images appeared. Our dataset contains 35 million images and web pages, totaling 25 terabytes of data. Finally, we released vectors representation of each image extracted using Scale Invariant Feature Transform (SIFT) features, color histograms and convolutional neural network (CNN) features from AlexNet.
The project paper "A Large Multilingual Corpus for Learning Translations from Images" that was submitted for EMNLP 2017 but ultimately rejected because "the authors have provided some imporatant examples and statistics in the supplementary material whereas the paper should be self-contained as mentioned in the call for papers."
INTRODUCTION

Machine translation typically require bilingual sentence-aligned parallel texts. However such texts often do no exist, in particular for low resource languages. In such cases researchers have explored various monolingual signals that is preserved across languages: from surface form of words to aligning SIFT image representation of words. Image represenation of words is ideal because it is both universal and plentiful: billions of images with associated labels can be readily retrieved across languages using Google search. In this project, we compared the efficacy of using image representation of words extracted by SIFT (scale invariant feature transform) and those learned by AlexNet for machine translation. We differentiate from prior dataset in both size and scope. Our data has 100 images covering over 260k words in English, and over 10k words in 100 foreign languages. Finally, our corpus include both concrete and non-concrete nouns. We introduced the methodology for creating the resources, in particular how we avoided recreating Google’s bilingual dictionaries used to query results for the image search, and reported a series of experiments that demonstrate the value of our images for machine translation.
TECHNICAL BACKGROUND
In this section we introduce SIFT, convolutional neural nets, and machine translation through multi-modal data. SIFT, or scale invariant feature transform are local image features that is invariant to scaling and rotation, they are robust to illumination, noise and distortion. Until the introduction of convolutional neural nets, SIFT is the most common local feature descriptor method in computer vision. For example, SIFT features may be extracted and concatenated to create a bag-of-words description for the image, which may be used in a regression model for classification. In fact, Bergsma and Van Durme used this bag-of-words representation to significantly increase the accuracy of translation in over 15 language pairs.

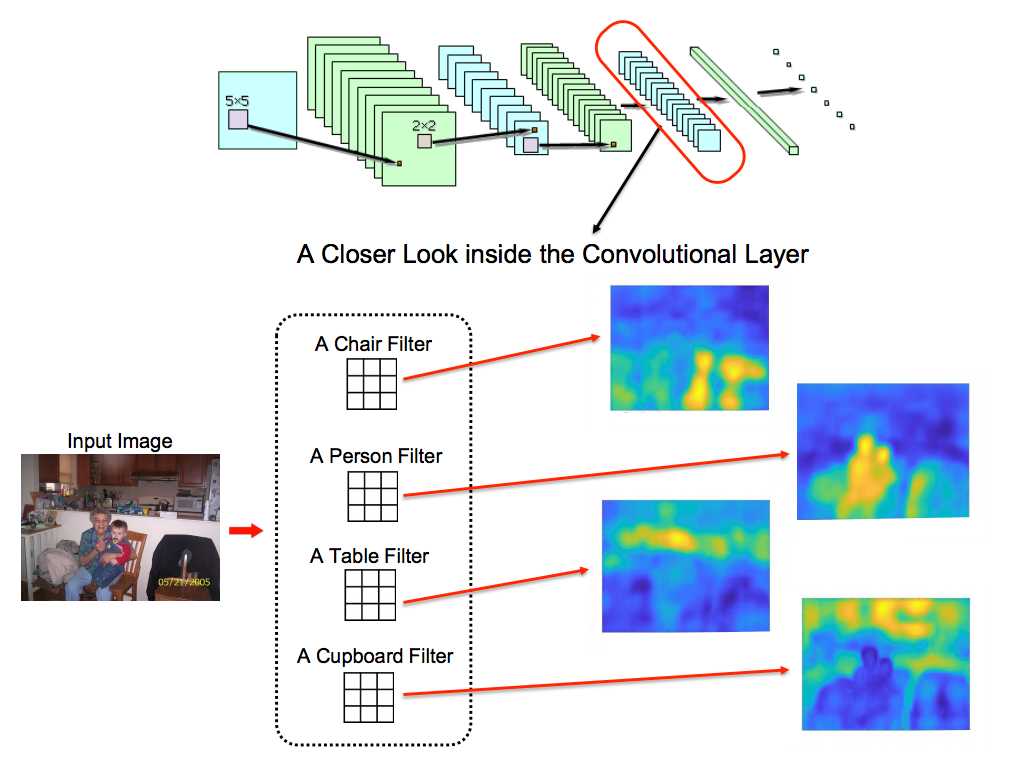
Since the late 2000s, convolutional neural networks (CNN) have replaced many traditional methods in computer vision due to cheaper computing power, deluge of data, and the fact that performance of CNNs continue to increase with the size of data while traditional methods often plateau. Contrary to some neural networks, features learned by CNNs are both informative and can be interpreted visually. In figures 3 - 6, we show that lower layers in the network capture local features similar to SIFT, while higher levels discriminate among class-level concepts. Empricially speaking, this makes the top layers of a convolutional neural net more informative representations of classes than SIFT across many tasks. Thus we hypothesized that CNNs could be ideal feature extractors for monolingual machine translation as well, whose goal is to discrminate among classes/words using sets of images.


CORPUS CREATION
We created our dataset by querying Google Image Search for images associated with the English and foreign words in 100 bilingual dictionaries. Specifically We constructed bilingual dictionaries from English onto 100 foreign languages, with 10k words in each dictionary. We discarded words where English and foreign words are identical. Then for each word in the dictionary, we queried Google Image search for images associated with the word in English and the foreign word. In order to prevent replication of Google's internal bilingual dictionary which may have been used to construct the return query, we cross-referenced the URL associated with the image to ensure the image appeared on the page. In addition, we filter out images from pages that is not from the target language. Over all, 100 images are retrieved per word for English and the foreign language, and we extracted feature representation of the words using SIFT with color histograms, and AlexNet.
RESULTS AND DISCUSSION
We use the following expression to find words with the closest translation, given sets of images ℰ from the source word e and ℱ from the target word f, the average top-matches are used to produce a single value:
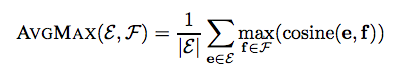
The model's ranking is evaluated using Mean Reciprocal Rank (MRR) and top-N accuracy. Unlike previous work which only translate among concrete nouns in high resource languages, we consider all words in our corpus, and amongst many low resource languages such as Uzbek and Urdu. When analyzing the results, we chose 500 most concrete words (often words that is grounded in one concept in reality, such as "car") and report the results separately. The concrete nouns are selected according the Ghent dataset.
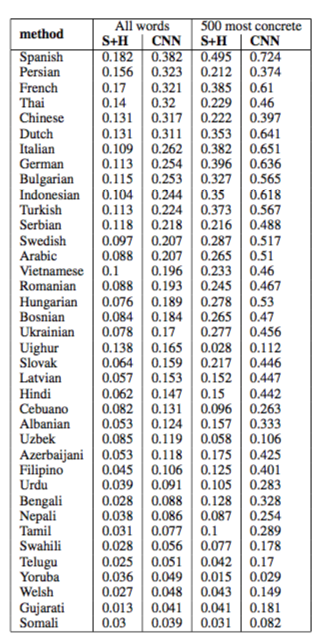
Given figure 7, it is clear that AlexNet out performs Sift and histogram features across the board, confirming our initial intuition. Furthermore, translation quality is higher for concrete nouns, which have a narrower distribution of images, than all words.
CONCLUSION
In this project, we created and released a new dataset to assess the value add of image similarity in machine translation. Our data set is significantly larger than prior attempts and cover high and low resource languages. We demonstrate the superior value of features extracted by AlexNet versus those from color histograms and SIFT. Furthermore, in the paper "Learning Translations via Matrix Completion", we show the features can be incorporated into a more general framework for machine translation. Finally, we have released the data set for open consumption via the LDC.